
Netty学习笔记 - 小滴
第一章:高并发编程Netty实战课程介绍
1、高并发编程Netty框架实战课程介绍
大纲
2、异步事件驱动NIO框架Netty介绍
简介:介绍Netty来源,版本,目前在哪些主流公司和产品框架使用
1、Netty是由JBOSS提供的一个java开源框架, 是业界最流行的NIO框架,整合了多种协议(
包括FTP、SMTP、HTTP等各种二进制文本协议)的实现经验,精心设计的框架,在多个大型商业项目中得到充分验证。
1)API使用简单
2)成熟、稳定
3)社区活跃 有很多种NIO框架 如mina
4)经过大规模的验证(互联网、大数据、网络游戏、电信通信行业)
2、那些主流框架产品在用?
1)搜索引擎框架 ElasticSerach
2) Hadopp子项目Avro项目,使用Netty作为底层通信框架
3)阿里巴巴开源的RPC框架 Dubbo
地址:http://dubbo.apache.org/zh-cn/
Netty在Dubbo里面使用的地址
https://github.com/apache/incubator-dubbo/tree/master/dubbo-remoting/dubbo-remoting-netty4/src/main/java/org/apache/dubbo/remoting/transport/netty4
补充:netty4是dubbo2.5.6后引入的,2.5.6之前的netty用的是netty3
3、高并发编程Netty实战课程开发环境准备
简介:讲解Netty实战开发环境
1、IDEA旗舰版/Eclipse + JDK8 + Maven3.5以上版本 + Netty4.x
Netty版本说明
采用最新的4.x版本,只要大版本一致就可以
官方文档: https://netty.io/wiki/user-guide-for-4.x.html
Github地址:https://github.com/netty/netty
第二章:使用JDK自带BIO编写一个Client-Server通信
1、BIO网络编程实战之编写BioServer服务端
简介: 使用jdk自带的Bio编写一个统一时间服务
2、BIO网络编程实战之编写BioClient客服端
简介:使用BIO网络编程编写BioClient客户端
3、BIO编写Client/Server通信优缺点分析
简介:讲解BIO的优缺点,为啥不能高并发情况下性能弱
优点:
模型简单
编码简单
缺点:
性能瓶颈,请求数和线程数 N:N关系
高并发情况下,CPU切换线程上下文损耗大
案例:web服务器Tomcat7之前,都是使用BIO,7之后就使用NIO
改进:伪NIO,使用线程池去处理业务逻辑
第三章:服务端网络编程常见网络IO模型讲解(面试核心)
1、什么是阻塞/非阻塞,什么是同/异步
简介:使用最通俗概念讲解 同步异步、堵塞和非堵塞
洗衣机洗衣服
- 同步阻塞:你把衣服丢到洗衣机洗,然后看着洗衣机洗完,洗好后再去晾衣服(你就干等,啥都不做,阻塞在那边)
- 同步非阻塞:你把衣服丢到洗衣机洗,然后会客厅做其他事情,定时去阳台看洗衣机是不是洗完了,洗好后再去晾衣服
(等待期间你可以做其他事情,比如用电脑看视频) - 异步阻塞: 你把衣服丢到洗衣机洗,然后看着洗衣机洗完,洗好后再去晾衣服(几乎没这个情况,几乎没这个说法,可以忽略)
- 异步非阻塞:你把衣服丢到洗衣机洗,然后会客厅做其他事情,洗衣机洗好后会自动去晾衣服,晾完成后放个音乐告诉你洗好衣服并晾好了
2、Linux网络编程中的五种I/O模型讲解
网络IO,用户程序和内核的交互为基础进行讲解
IO操作分两步:
-
发起IO请求等待数据准备,
-
实际IO操作(洗衣服,晾衣服)
-
同步须要主动读写数据,在读写数据的过程中还是会阻塞(好比晾衣服阻塞了你)
-
异步仅仅须要I/O操作完毕的通知。并不主动读写数据,由操作系统内核完毕数据的读写(机器人帮你自动晾衣服)
五种IO的模型:
- 阻塞IO
- 非阻塞IO
- 多路复用IO
- 信号驱动IO
- 异步IO
前四种都是同步IO,在内核数据copy到用户空间时都是阻塞的
权威:RFC标准,或者书籍 《UNIX Network Programming》中文名《UNIX网络编程-卷一》第六章
1)阻塞式I/O;
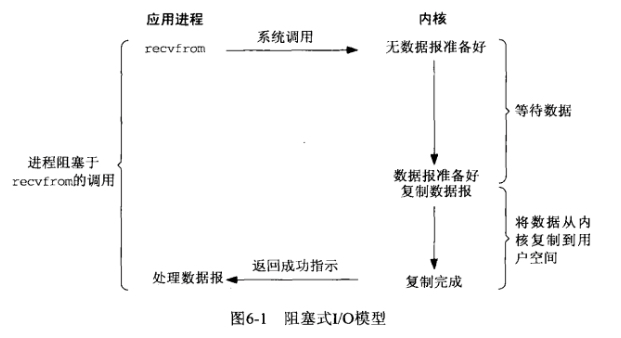
2)非阻塞式I/O;
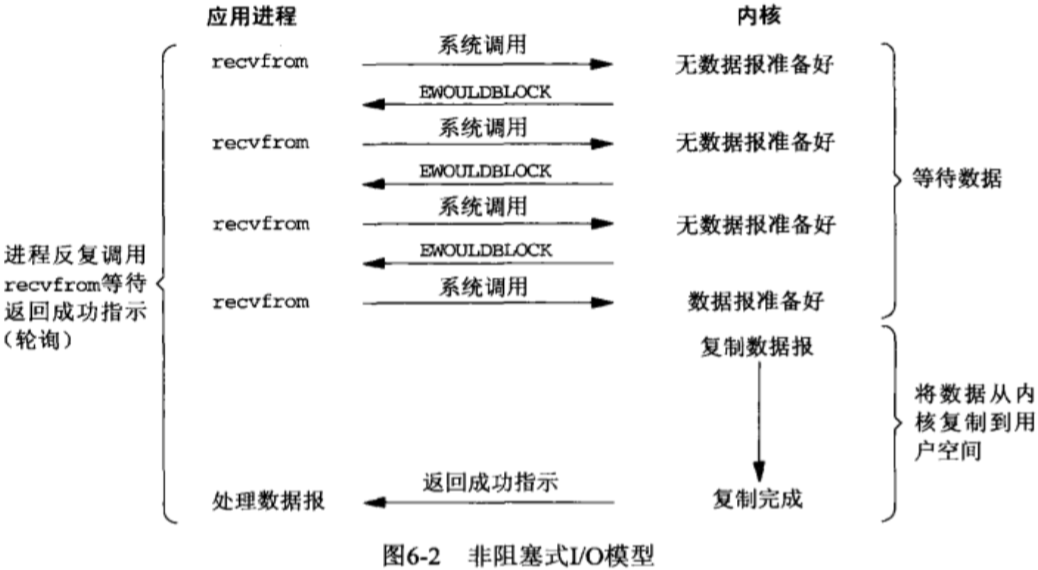
3)I/O复用(select,poll,epoll...);
I/O多路复用是阻塞在select,epoll这样的系统调用,没有阻塞在真正的I/O系统调用如recvfrom
进程受阻于select,等待可能多个套接口中的任一个变为可读
IO多路复用使用两个系统调用(select和recvfrom)
blocking IO只调用了一个系统调用(recvfrom)
select/epoll 核心是可以同时处理多个connection,而不是更快,所以连接数不高的话,性能不一定比多线程+阻塞IO好
多路复用模型中,每一个socket,设置为non-blocking,
阻塞是被select这个函数block,而不是被socket阻塞的
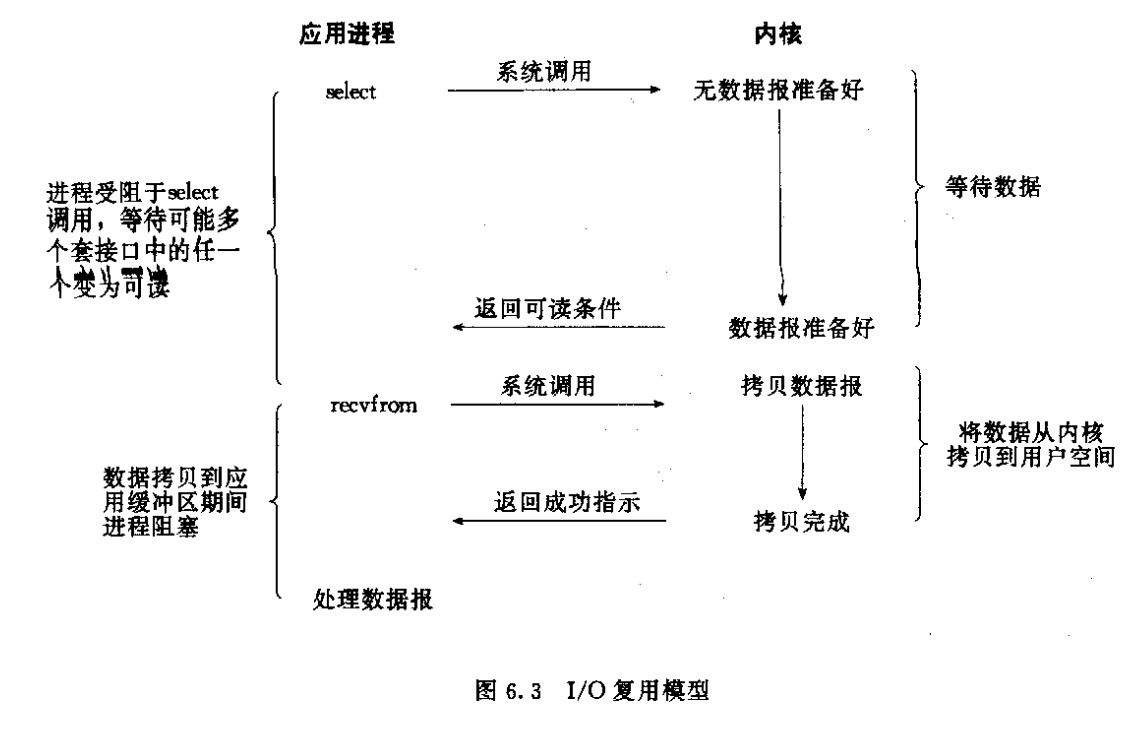
4)信号驱动式I/O(SIGIO);
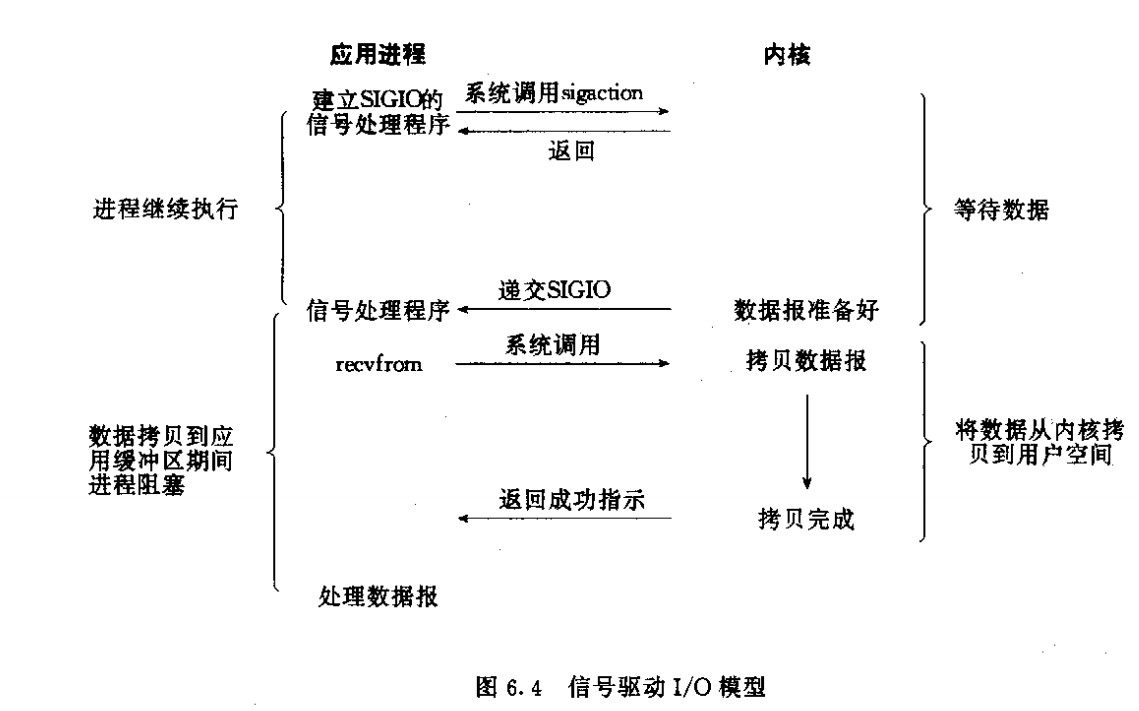
5)异步I/O(POSIX的aio_系列函数) Future-Listener机制;
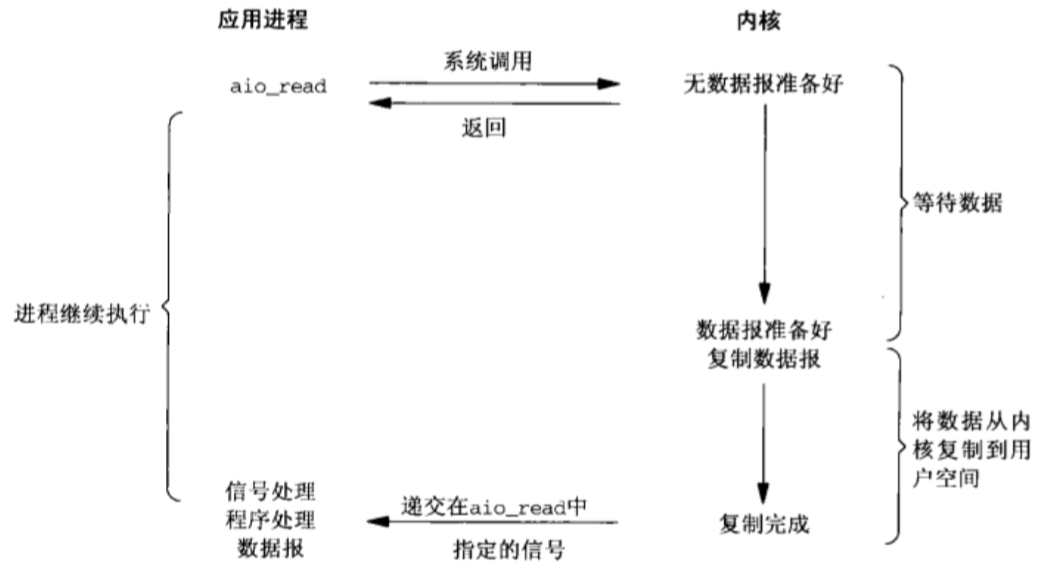
IO操作分为两步
- 发起IO请求,等待数据准备(Waiting for the data to be ready)
- 实际的IO操作,将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
-
前四种IO模型都是同步IO操作,
- 区别在于第一阶段,
- 第二阶段是一样的:在数据从内核复制到应用缓冲区期间(用户空间),进程阻塞于recvfrom调用或者select()函数。
-
异步I/O模型在这两个阶段都处理
-
阻塞IO和非阻塞IO的区别在于第一步,发起IO请求是否会被阻塞,
- 如果阻塞,直到完成那么就是传统的阻塞IO,
- 如果不阻塞,那么就是非阻塞IO。
-
同步IO和异步IO的区别就在于第二个步骤是否阻塞,如果实际的IO读写阻塞请求进程,那么就是同步IO,
- 因此阻塞IO、非阻塞IO、IO复用、信号驱动IO都是同步IO,
- 如果不阻塞,而是操作系统帮你做完IO操作再将结果返回给你,那么就是异步IO。
几个核心点:
- 阻塞非阻塞说的是线程的状态(重要)
- 同步和异步说的是消息的通知机制(重要)
- 同步需要主动读写数据,异步是不需要主动读写数据
- 同步IO和异步IO是针对用户应用程序和内核的交互
拓展阅读:
IO模型进化历史:https://www.zhihu.com/question/59975081
4、 IO多路复用技术
简介:高并发编程必备知识IO多路复用技术select、poll讲解
什么是IO多路复用
I/O多路复用,I/O是指网络I/O, 多路指多个TCP连接(即socket或者channel),复用指复用一个或几个线程。
简单来说:就是使用一个或者几个线程处理多个TCP连接
最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程
select
-
基本原理:
监视文件3类描述符: writefds、readfds、和exceptfds
调用后select函数会阻塞住,等有数据 可读、可写、出异常 或者 超时 就会返回
select函数正常返回后,通过遍历fdset整个数组才能发现哪些句柄发生了事件,来找到就绪的描述符fd,然后进行对应的IO操作
几乎在所有的平台上支持,跨平台支持性好 -
缺点:
1)select采用轮询的方式扫描文件描述符,全部扫描,随着文件描述符FD数量增多而性能下降
2)每次调用 select(),需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)
3)最大的缺陷就是单个进程打开的FD有限制,默认是1024 (可修改宏定义,但是效率仍然慢)
static final int MAX_FD = 1024
poll
基本流程:
select() 和 poll() 系统调用的大体一样,处理多个描述符也是使用轮询的方式,根据描述符的状态进行处理
一样需要把 fd 集合从用户态拷贝到内核态,并进行遍历。
最大区别是: poll没有最大文件描述符限制(使用链表的方式存储fd)
epoll
-
基本原理:
在2.6内核中提出的,对比select和poll,epoll更加灵活,没有描述符限制,用户态拷贝到内核态只需要一次
使用事件通知,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用callback的回调机制来激活对应的fd -
优点:
1)没fd这个限制,所支持的FD上限是操作系统的最大文件句柄数,1G内存大概支持10万个句柄
2)效率提高,使用回调通知而不是轮询的方式,不会随着FD数目的增加效率下降
2)通过callback机制通知,内核和用户空间mmap同一块内存实现 -
Linux内核核心函数
1)epoll_create() 在Linux内核里面申请一个文件系统 B+树,返回epoll对象,也是一个fd
2)epoll_ctl() 操作epoll对象,在这个对象里面修改添加删除对应的链接fd, 绑定一个callback函数
3)epoll_wait() 判断并完成对应的IO操作 -
缺点:
编程模型比select/poll 复杂
例子:100万个连接,里面有1万个连接是活跃,在 select、poll、epoll分别是怎样的表现
select:不修改宏定义,则需要 1000个进程才可以支持 100万连接
poll:100万个链接,遍历都响应不过来了,还有空间的拷贝消耗大量的资源
epoll:
6、Java的I/O演进历史
简介:讲解java的IO演进历史
1、jdk1.4之前是采用同步阻塞模型,也就是BIO
大型服务一般采用C或者C++, 因为可以直接操作系统提供的异步IO,AIO
2、jdk1.4推出NIO,支持非阻塞IO,jdk1.7升级,推出NIO2.0,提供AIO的功能,支持文件和网络套接字的异步IO
7、大话Netty线程模型和Reactor模式
简介:讲解reactor模式 和 Netty线程模型
设计模式——Reactor模式(反应器设计模式),是一种基于事件驱动的设计模式,在事件驱动的应用中,将一个或多个客户的服务请求分离(demultiplex)和调度(dispatch)给应用程序。在事件驱动的应用中,同步地、有序地处理同时接收的多个服务请求
一般出现在高并发系统中,比如Netty,Redis等
-
优点
1)响应快,不会因为单个同步而阻塞,虽然Reactor本身依然是同步的;
2)编程相对简单,最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销;
3)可扩展性,可以方便的通过增加Reactor实例个数来充分利用CPU资源; -
缺点
1)相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
2)Reactor模式需要系统底层的的支持,比如Java中的Selector支持,操作系统的select系统调用支持
通俗理解:KTV例子 前台接待,服务人员带领去开机器
Reactor模式基于事件驱动,适合处理海量的I/O事件,属于同步非阻塞IO(NIO)
Reactor单线程模型(比较少用)
内容:
1)作为NIO服务端,接收客户端的TCP连接;作为NIO客户端,向服务端发起TCP连接;
2)服务端读请求数据并响应;客户端写请求并读取响应
使用场景:
对应小业务则适合,编码简单;对于高负载、大并发的应用场景不适合,一个NIO线程处理太多请求,则负载过高,并且可能响应变慢,导致大量请求超时,而且万一线程挂了,则不可用了
Reactor多线程模型
内容:
1)一个Acceptor线程,一组NIO线程,一般是使用自带的线程池,包含一个任务队列和多个可用的线程
使用场景:
可满足大多数场景,但是当Acceptor需要做复杂操作的时候,比如认证等耗时操作,再高并发情况下则也会有性能问题
Reactor主从线程模型
内容:
- Acceptor不在是一个线程,而是一组NIO线程;IO线程也是一组NIO线程,这样就是两个线程池去处理接入连接和处理IO
使用场景:
满足目前的大部分场景,也是Netty推荐使用的线程模型
BossGroup
WorkGroup
附属资料:为什么Netty使用NIO而不是AIO,是同步非阻塞还是异步非阻塞?
答案:
在Linux系统上,AIO的底层实现仍使用EPOLL,与NIO相同,因此在性能上没有明显的优势
Netty整体架构是reactor模型,采用epoll机制,所以往深的说,还是IO多路复用模式,所以也可说netty是同步非阻塞模型(看的层次不一样)
很多人说这是netty是基于Java NIO 类库实现的异步通讯框架
特点:异步非阻塞、基于事件驱动,性能高,高可靠性和高可定制性。
参考资料:
https://github.com/netty/netty/issues/2515
第四章:Netty第一个案例
1、讲解什么是Echo服务和Netty项目搭建
简介:讲解什么是Echo服务和快速创建Netty项目
1)什么是Echo服务:就是一个应答服务(回显服务器),客户端发送什么数据,服务端就响应的对应的数据
是一个非常有的用于调试和检测的服务
2)IDEA + Maven + jdk8
netty依赖包
3) maven地址:https://mvnrepository.com/artifact/io.netty/netty-all/4.1.32.Final
2、Netty实战之Echo服务-服务端程序编写实战
简介:讲解Echo服务-服务端程序编写实战,对应的启动类和handler处理器
3、Netty实战之Echo服务-客户端程序编写实战
简介:讲解Echo服务客户端程序编写
4、Netty实战之Echo服务演示和整个流程分析
简介:分析整个Echo服务各个组件名称和作用
1)EventLoop和EventLoopGroup
2) Bootstrapt启动引导类
3)Channel 生命周期,状态变化
4)ChannelHandler和ChannelPipline
第五章:核心链路源码讲解
1、深入剖析EventLoop和EventLoopGroup线程模型
简介:源码讲解EventLoop和EventLoopGroup模块
1)高性能RPC框架的3个要素:IO模型、数据协议、线程模型
2)EventLoop好比一个线程,1个EventLoop可以服务多个Channel,1个Channel只有一个EventLoop
可以创建多个 EventLoop 来优化资源利用,也就是EventLoopGroup
3)EventLoopGroup 负责分配 EventLoop 到新创建的 Channel,里面包含多个EventLoop
EventLoopGroup -> 多个 EventLoop
EventLoop -> 维护一个 Selector
学习资料:http://ifeve.com/selectors/
4)源码分析默认线程池数量
2、Netty启动引导类Bootstrap模块讲解
简介:讲解Netty启动引导类Bootstrap作用和tcp通道参数设置
参考:https://blog.csdn.net/QH_JAVA/article/details/78383543
2.1. 服务器启动引导类ServerBootstrap
- group :设置线程组模型,Reactor线程模型对比EventLoopGroup
1)单线程
2)多线程
3)主从线程
参考:https://blog.csdn.net/QH_JAVA/article/details/78443646
2)channel:设置channel通道类型NioServerSocketChannel、OioServerSocketChannel
- option: 作用于每个新建立的channel,设置TCP连接中的一些参数,如下
- ChannelOption.SO_BACKLOG: 存放已完成三次握手的请求的等待队列的最大长度;
- Linux服务器TCP连接底层知识:
- syn queue:半连接队列,洪水攻击,tcp_max_syn_backlog
- accept queue:全连接队列, net.core.somaxconn
- Linux服务器TCP连接底层知识:
- 系统默认的somaxconn参数要足够大 ,如果backlog比somaxconn大,则会优先用后者
- ChannelOption.TCP_NODELAY: 为了解决Nagle的算法问题,默认是false, 要求高实时性,有数据时马上发送,就将该选项设置为true关闭Nagle算法;如果要减少发送次数,就设置为false,会累积一定大小后再发送;
- 知识拓展:
- https://baike.baidu.com/item/Nagle%E7%AE%97%E6%B3%95/5645172
- https://www.2cto.com/article/201309/241096.html
4)childOption: 作用于被accept之后的连接
- childHandler: 用于对每个通道里面的数据处理
2.2. 客户端启动引导类Bootstrap
1)remoteAddress: 服务端地址
2)handler:和服务端通信的处理器
3、Netty核心组件Channel模块讲解
简介:讲解Channel作用,核心模块知识点,生命周期等
什么是Channel: 客户端和服务端建立的一个连接通道
什么是ChannelHandler: 负责Channel的逻辑处理
什么是ChannelPipeline: 负责管理ChannelHandler的有序容器
他们是什么关系:
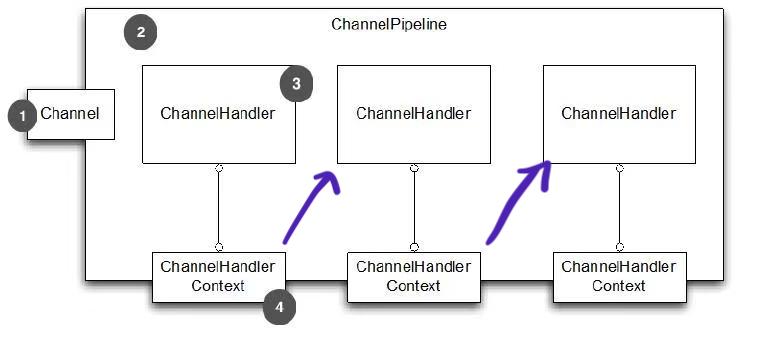
- 一个Channel包含一个ChannelPipeline,所有ChannelHandler都会顺序加入到ChannelPipeline中
- 创建Channel时会自动创建一个ChannelPipeline,每个Channel都有一个管理它的pipeline,这关联是永久性的
Channel当状态出现变化,就会触发对应的事件
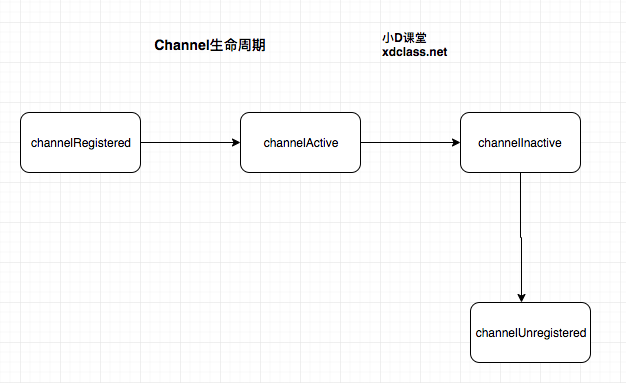
状态:
(1)channelRegistered: channel注册到一个EventLoop
(2)channelActive: 变为活跃状态(连接到了远程主机),可以接受和发送数据
(3)channelInactive: channel处于非活跃状态,没有连接到远程主机
(4)channelUnregistered: channel已经创建,但是未注册到一个EventLoop里面,也就是没有和Selector绑定
4、ChannelHandler和ChannelPipeline模块讲解
简介:讲解ChannelHandler和ChannelPipeline核心作用和生命周期
方法:
handlerAdded : 当 ChannelHandler 添加到 ChannelPipeline 调用
handlerRemoved : 当 ChannelHandler 从 ChannelPipeline 移除时调用
exceptionCaught : 执行抛出异常时调用
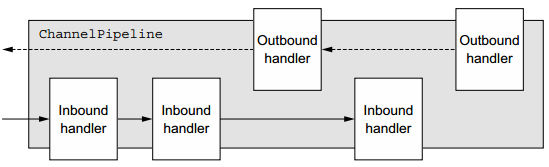
ChannelHandler下主要是两个子接口
- ChannelInboundHandler:(入站)
- 处理输入数据和Channel状态类型改变,
- 适配器 ChannelInboundHandlerAdapter(适配器设计模式)
- 常用的:SimpleChannelInboundHandler
- ChannelOutboundHandler:(出站)
- 处理输出数据,适配器 ChannelOutboundHandlerAdapter
ChannelPipeline:
好比厂里的流水线一样,可以在上面添加多个ChannelHanler,也可看成是一串 ChannelHandler 实例,拦截穿过 Channel 的输入输出 event, ChannelPipeline 实现了拦截器的一种高级形式,使得用户可以对事件的处理以及ChannelHanler之间交互获得完全的控制权
5、Netty核心模块指ChannelHandlerContext模块讲解
简介:讲解ChannelHandlerContext模块的作用和分析
1、ChannelHandlerContext是连接ChannelHandler和ChannelPipeline的桥梁
ChannelHandlerContext部分方法和Channel及ChannelPipeline重合,好比调用write方法,
Channel、ChannelPipeline、ChannelHandlerContext 都可以调用此方法,前两者都会在整个管道流里传播,而ChannelHandlerContext就只会在后续的Handler里面传播
2、AbstractChannelHandlerContext类
双向链表结构,next/prev分别是后继节点,和前驱节点
3、DefaultChannelHandlerContext 是实现类,但是大部分都是父类那边完成,这个只是简单的实现一些方法
主要就是判断Handler的类型。
ChannelInboundHandler之间的传递,主要通过调用ctx里面的fireXXX()方法来实现下个handler的调用
6、Netty案例实战常见问题之入站出站Handler执行顺序
简介: 讲解多个入站出站ChannelHandler的执行顺序
问题
一般的项目中,inboundHandler和outboundHandler有多个,在Pipeline中的执行顺序?
回答
InboundHandler顺序执行,OutboundHandler逆序执行
问题:ch.pipeline().addLast(new InboundHandler1());
ch.pipeline().addLast(new OutboundHandler1());
ch.pipeline().addLast(new OutboundHandler2());
ch.pipeline().addLast(new InboundHandler2());
或者:
ch.pipeline().addLast(new OutboundHandler1());
ch.pipeline().addLast(new OutboundHandler2());
ch.pipeline().addLast(new InboundHandler1());
ch.pipeline().addLast(new InboundHandler2());
执行顺序是:
InboundHandler1 channelRead
InboundHandler2 channelRead
OutboundHandler2 write
OutboundHandler1 write
结论
1)InboundHandler顺序执行,OutboundHandler逆序执行
2)InboundHandler之间传递数据,通过ctx.fireChannelRead(msg)
3)InboundHandler通过ctx.write(msg),则会传递到outboundHandler
4) 使用ctx.write(msg)传递消息,Inbound需要放在结尾,在Outbound之后,不然outboundhandler会不执行;
但是使用channel.write(msg)、pipline.write(msg)情况会不一致,都会执行
5) outBound和Inbound谁先执行,针对客户端和服务端而言,客户端是发起请求再接受数据,先outbound再inbound,服务端则相反
7、Netty异步操作模块ChannelFuture讲解
简介:讲解ChannelFuture异步操作模块及使用注意事项
Netty中的所有I/O操作都是异步的,这意味着任何I/O调用都会立即返回,而ChannelFuture会提供有关的信息I/O操作的结果或状态。
1)ChannelFuture状态:
-
未完成:当I/O操作开始时,将创建一个新的对象,新的最初是未完成的 - 它既没有成功,也没有成功,也没有被取消,因为I/O操作尚未完成。
-
已完成:当I/O操作完成,不管是成功、失败还是取消,Future都是标记为已完成的, 失败的时候也有具体的信息,例如原因失败,但请注意,即使失败和取消属于完成状态。
-
注意:
- 不要在IO线程内调用future对象的sync或者await方法
- 不能在channelHandler中调用sync或者await方法
2)ChannelPromise:继承于ChannelFuture,进一步拓展用于设置IO操作的结果
第六章:网络数据传输编解码
1、什么是编码、解码
简介:讲解Netty编写的网络数据传输中的编码和解码
前面说的:高性能RPC框架的3个要素:IO模型、数据协议、线程模型
最开始接触的编码码:java序列化/反序列化(就是编解码)、url编码、base64编解码
为啥jdk有编解码,还要netty自己开发编解码?
java自带序列化的缺点
1)无法跨语言
2) 序列化后的码流太大,也就是数据包太大
3) 序列化和反序列化性能比较差
业界里面也有其他编码框架: google的 protobuf(PB)、Facebook的Trift、Jboss的Marshalling、Kyro等
Netty里面的编解码:
解码器:负责处理“入站 InboundHandler”数据
编码器:负责“出站 OutboundHandler” 数据
Netty里面提供默认的编解码器,也支持自定义编解码器
Encoder:编码器
Decoder:解码器
Codec:编解码器
2、解码器Decoder讲解
简介:讲解Netty的解码器Decoder和使用场景
Decoder对应的就是ChannelInboundHandler,主要就是字节数组转换为消息对象
主要是两个方法
decode
decodeLast
抽象解码器
1)ByteToMessageDecoder
用于将字节转为消息,需要检查缓冲区是否有足够的字节
2)ReplayingDecoder
继承ByteToMessageDecoder,不需要检查缓冲区是否有足够的字节,但是ReplayingDecoder速度略满于ByteToMessageDecoder,不是所有的ByteBuf都支持
选择:项目复杂性高则使用ReplayingDecoder,否则使用 ByteToMessageDecoder
3)MessageToMessageDecoder
用于从一种消息解码为另外一种消息(例如POJO到POJO)
解码器具体的实现
用的比较多的是(更多是为了解决TCP底层的粘包和拆包问题)
- DelimiterBasedFrameDecoder: 指定消息分隔符的解码器
- LineBasedFrameDecoder: 以换行符为结束标志的解码器
- FixedLengthFrameDecoder:固定长度解码器
- LengthFieldBasedFrameDecoder:message = header+body, 基于长度解码的通用解码器
- StringDecoder:文本解码器,将接收到的对象转化为字符串,一般会与上面的进行配合,然后在后面添加业务handle
3、编码器Encoder讲解
简介:讲解Netty编码器Encoder
Encoder对应的就是ChannelOutboundHandler,消息对象转换为字节数组
Netty本身未提供和解码一样的编码器,是因为场景不同,两者非对等的
1)MessageToByteEncoder
消息转为字节数组,调用write方法,会先判断当前编码器是否支持需要发送的消息类型,如果不支持,则透传;
2)MessageToMessageEncoder
用于从一种消息编码为另外一种消息(例如POJO到POJO)
4、数据协议处理之Netty编解码器类Codec讲解
简介:讲解组合编解码器类Codec
组合解码器和编码器,以此提供对于字节和消息都相同的操作
优点:成对出现,编解码都是在一个类里面完成
缺点:耦合在一起,拓展性不佳
Codec:组合编解码
1)ByteToMessageCodec
2)MessageToMessageCodec
decoder:解码
1)ByteToMessageDecoder
2)MessageToMessageDecoder
encoder:编码
1)ByteToMessageEncoder
2)MessageToMessageEncoder
第七章:网络传输TCP粘包拆包
1、网络编程核心知识之TCP粘包拆包讲解
简介:讲解什么是TCP粘包拆包讲解
1)TCP拆包: 一个完整的包可能会被TCP拆分为多个包进行发送
2)TCP粘包: 把多个小的包封装成一个大的数据包发送, client发送的若干数据包 Server接收时粘成一包
出现的原因
- 发送方的原因:TCP默认会使用Nagle算法
- 接收方的原因: TCP接收到数据放置缓存中,应用程序从缓存中读取
UDP: 是没有粘包和拆包的问题,有边界协议
2、TCP半包读写常见解决方案
简介:讲解TCP半包读写常见的解决办法
发送方:可以关闭Nagle算法
接受方: TCP是无界的数据流,并没有处理粘包现象的机制, 且协议本身无法避免粘包,半包读写的发生需要在应用层进行处理
应用层解决半包读写的办法
1)设置定长消息 (10字符)
xdclass000xdclass000xdclass000xdclass000
2)设置消息的边界 (
dsafadfadsfwqehidwuehfiw
\[879329832r89qweew \] 3)使用带消息头的协议,消息头存储消息开始标识及消息的长度信息
Header+Body
3、Netty自带解决TCP半包读写方案
简介:讲解Netty自带解决半包读写问题方案介绍
- DelimiterBasedFrameDecoder: 指定消息分隔符的解码器
- LineBasedFrameDecoder: 以换行符为结束标志的解码器
- FixedLengthFrameDecoder:固定长度解码器
- LengthFieldBasedFrameDecoder:message = header+body, 基于长度解码的通用解码器
4、Netty案例实战之半包读写问题演示
简介:案例实战之使用netty进行开发,出现的TCP半包读写问题
5、Netty案例实战之LineBasedFrameDecoder解决TCP半包读写
简介:讲解使用解码器LineBasedFrameDecoder解决半包读写问题
1)LineBaseFrameDecoder 以换行符为结束标志的解码器 ,构造函数里面的数字表示最长遍历的帧数
2)StringDecoder解码器将对象转成字符串
6、Netty案例实战之自定义分隔符解决TCP读写问题
简介:讲解使用DelimiterBasedFrameDecoder解决TCP半包读写问题
- maxLength:
- 表示一行最大的长度,如果超过这个长度依然没有检测自定义分隔符,将会抛出TooLongFrameException
- failFast:
- 如果为true,则超出maxLength后立即抛出TooLongFrameException,不进行继续解码
- 如果为false,则等到完整的消息被解码后,再抛出TooLongFrameException异常
- stripDelimiter:
- 解码后的消息是否去除掉分隔符
- delimiters:
- 分隔符,ByteBuf类型
7、自定义长度半包读写器LengthFieldBasedFrameDecoder讲解
简介:自定义长度半包读写器LengthFieldBasedFrameDecoder讲解
官方文档:https://netty.io/4.0/api/io/netty/handler/codec/LengthFieldBasedFrameDecoder.html
- maxFrameLength
- 数据包的最大长度
- lengthFieldOffset
- 长度字段的偏移位,长度字段开始的地方,意思是跳过指定长度个字节之后的才是消息体字段
- lengthFieldLength
- 长度字段占的字节数, 帧数据长度的字段本身的长度
- lengthAdjustment
- 一般 Header + Body,添加到长度字段的补偿值,如果为负数,开发人员认为这个 Header的长度字段是整个消息包的长度,则Netty应该减去对应的数字
- initialBytesToStrip
- 从解码帧中第一次去除的字节数, 获取完一个完整的数据包之后,忽略前面的指定位数的长度字节,应用解码器拿到的就是不带长度域的数据包
- failFast
- 是否快速失败
第八章:Netty源码分析之基础数据传输讲解和设计模式
1、Netty核心模块缓冲ByteBuf
简介:讲解Netty核心之ByteBuf介绍,对比JDK原生ByteBuffer
ByteBuf:是数据容器(字节容器)
JDK ByteBuffer
共用读写索引,每次读写操作都需要Flip()
扩容麻烦,而且扩容后容易造成浪费
Netty ByteBuf
读写使用不同的索引,所以操作便捷
自动扩容,使用便捷
2、Netty数据存储模块ByteBuf创建方法和常用的模式
简介:讲解ByteBuf创建方法和常用的模式
ByteBuf:传递字节数据的容器
ByteBuf的创建方法
1)ByteBufAllocator
池化(Netty4.x版本后默认使用 PooledByteBufAllocator
提高性能并且最大程度减少内存碎片
非池化UnpooledByteBufAllocator: 每次返回新的实例
2)Unpooled: 提供静态方法创建未池化的ByteBuf,可以创建堆内存和直接内存缓冲区
ByteBuf使用模式
堆缓存区HEAP BUFFER:
优点:存储在JVM的堆空间中,可以快速的分配和释放
缺点:每次使用前会拷贝到直接缓存区(也叫堆外内存)
直接缓存区DIRECR BUFFER:
优点:存储在堆外内存上,堆外分配的直接内存,不会占用堆空间
缺点:内存的分配和释放,比在堆缓冲区更复杂
复合缓冲区COMPOSITE BUFFER:
可以创建多个不同的ByteBuf,然后放在一起,但是只是一个视图
选择:大量IO数据读写,用“直接缓存区”; 业务消息编解码用“堆缓存区”
3、Netty里面的设计模式应用分析
简介:讲解设计模式的在Netty里面的应用
- Builder构造器模式:ServerBootstap
- 责任链设计模式:pipeline的事件传播
- 工厂模式: 创建Channel
- 适配器模式:HandlerAdapter
推荐书籍:《Head First设计模式》
第九章:使用Netty搭建单机百万连接测试实战
1、搭建单机百万连接的服务器实例的必备知识
简介:搭建单机百万连接的服务器实例的必备知识
1、网络IO模型
2、Linux文件描述符
单进程文件句柄数(默认1024,不同系统不一样,每个进程都有最大的文件描述符限制)
全局文件句柄数
3、如何确定一个唯一的TCP连接
TCP四元组:源IP地址、源端口、目的ip、目的端口
2、Netty单机百万连接实战之服务端代码编写
简介:讲解Netty单机百万连接服务端代码编写
3、Netty单机百万连接实战之客户端代码编写
简介:讲解Netty单机百万连接之客户端代码编写
4、阿里云服务器Netty单机百万连接部署实战
简介:在阿里云服务器部署Netty服务端和Netty客户端代码
(如果没条件,则自己搭建虚拟机 6G,4核,centos6.5/7,需要关闭防火墙,或者使用云服务器需要开放安全组)
5、Netty单机百万连接Linux内核参数优化
简介:单机百万连接Linux核心参数优化
局部文件句柄限制
- 说明
- 单个进程最大文件打开数
- 一个进程最大打开的文件数 fd 不同系统有不同的默认值
- 查看
- ulimit -n
- 修改
- root身份编辑,
sudo vim /etc/security/limits.conf - 增加下面:
*表示当前用户,修改后要重启
- root身份编辑,
root soft nofile 1000000
root hard nofile 1000000
* soft nofile 1000000
* hard nofile 1000000
全局文件句柄限制
- 说明
- 所有进程最大打开的文件数,不同系统是不一样,可以直接echo临时修改
- 查看命令
- cat /proc/sys/fs/file-max
- 永久修改全局文件句柄,
- sudo vim /etc/sysctl.conf
- 增加 fs.file-max = 1000000
- 修改后生效 sysctl -p
启动
java -jar millionServer-1.0-SNAPSHOT.jar -Xms5g -Xmx5g -XX:NewSize=3g -XX:MaxNewSize=3g
6、互联网架构数据链路分析总结
简介:讲解当下互联网架构中,数据链路分析总结
输入域名-》浏览器内核调度-》本地DNS解析-》远程DNS解析-》ip -》路由多层调转-》目的服务器
服务器内核-》代理服务器 nginx/ 网关 / 负载均衡设备-》目的服务器
服务器内核-》 应用程序(springboot)-》Redis-》Mysql
第十章:高并发系列之百万连接Netty实战课程总结
1、高并发系列之百万连接Netty实战课程总结
简介:总结Netty实战课程和第二季展望
websocket
推送系统
RPC框架
《Netty权威指南》《Netty进阶之路》