
Netty学习笔记 - 李林锋
第一章:初识Netty:背景、现状与趋势
揭开 Netty 面纱
- 作者
- 概述
- 代码模块
- helloworld
为什么舍近求远:不直接用 JDK NIO
- 做的更多
- 支持常用应用层协议;
- 解决传输问题:粘包、半包现象;
- 支持流量整形;
- 完善的断连、Idle 等异常处理等
- 做的更好
- 避免jdk nio 的bug
- API更好更强大
- 隔离变化、屏蔽细节
- 避免花大量时间造轮子
- netty社区活跃,发展情景明朗
为什么孤注一掷:独选 Netty ?
- 相比mina:同作者推荐
- 相比grizzy:更新多、文档多用的多
- 为什么不选 Apple SwfitNIO 、ACE 等:其他语言
- 为什么不选 Cindy 等:生命周期不长。
- 为什么不选 Tomcat、Jetty :还没有独立出来。
Netty 的前尘往事
- 从归属组织上看发展
- 从版本演变上看发展
- 社区现状
- 最新版本
Netty 的现状与趋势
- 应用现状
- 一些典型项目
- 趋势
第二章:Netty 源码:从“点”(领域知识)的角度剖析
1. Netty 怎么切换三种 I/O 模式
- 什么是经典的三种 I/O 模式
- 一个吃饭的例子
- Netty 对三种 I/O 模式的支持
- BIO:过时
- NIO:common、linux、bsd
- AIO:移除
- 为什么 Netty 仅支持 NIO 了?
- BIO
- AIO
- 为什么 Netty 有多种 NIO 实现?
- 更多功能
- 更好性能
- NIO 一定优于 BIO 么?
- 仅在高并发时
- 源码解读 Netty 怎么切换 I/O 模式?
- EventLoopGroup
- 线程池
- 工厂模式+泛型+反射实现
- ServerSocketChannel
- 如何处理链接
- 为什么服务器开发并不需要切换客户端对应NioSocketChannel ?
- ServerSocketChannel 负责创建对应的 SocketChannel 。
- EventLoopGroup
2. Netty 如何支持三种 Reactor
2.1. 什么是Reactor模式?

2.2. Reactor模式的图示
-
Thread-Per-Connection模式
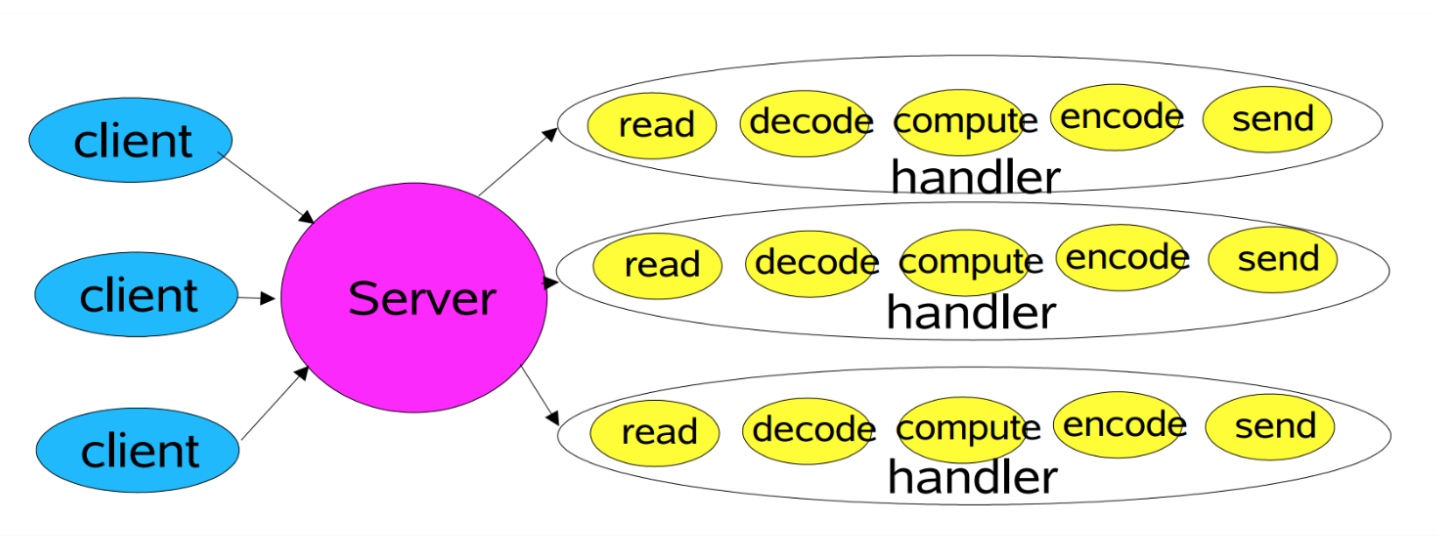
-
Reactor模式v1:单线程
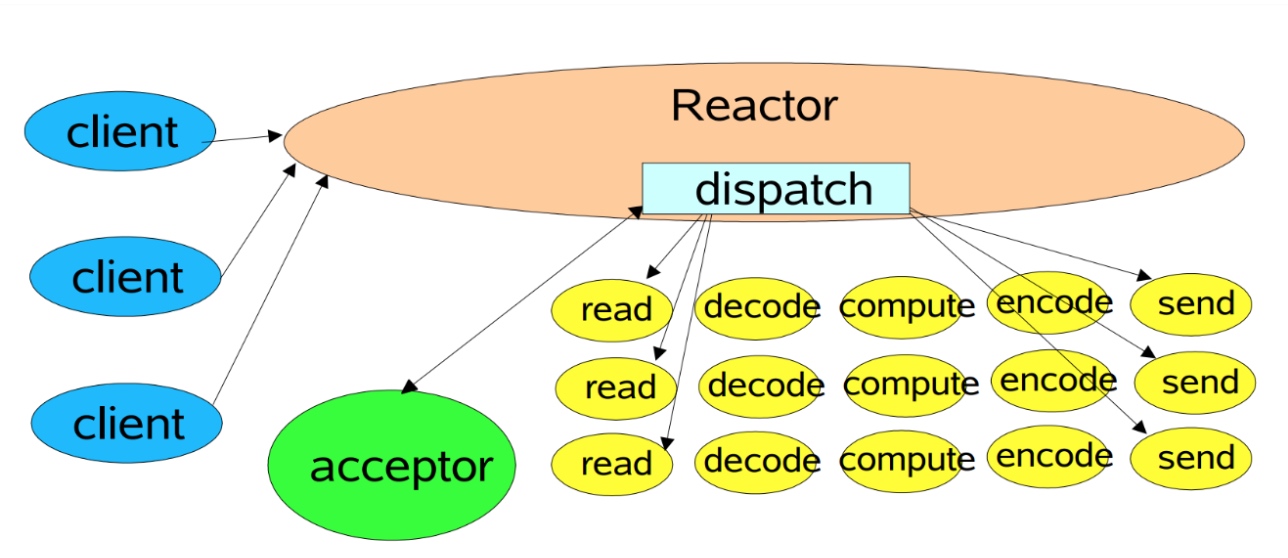
-
Reactor模式v2:多线程
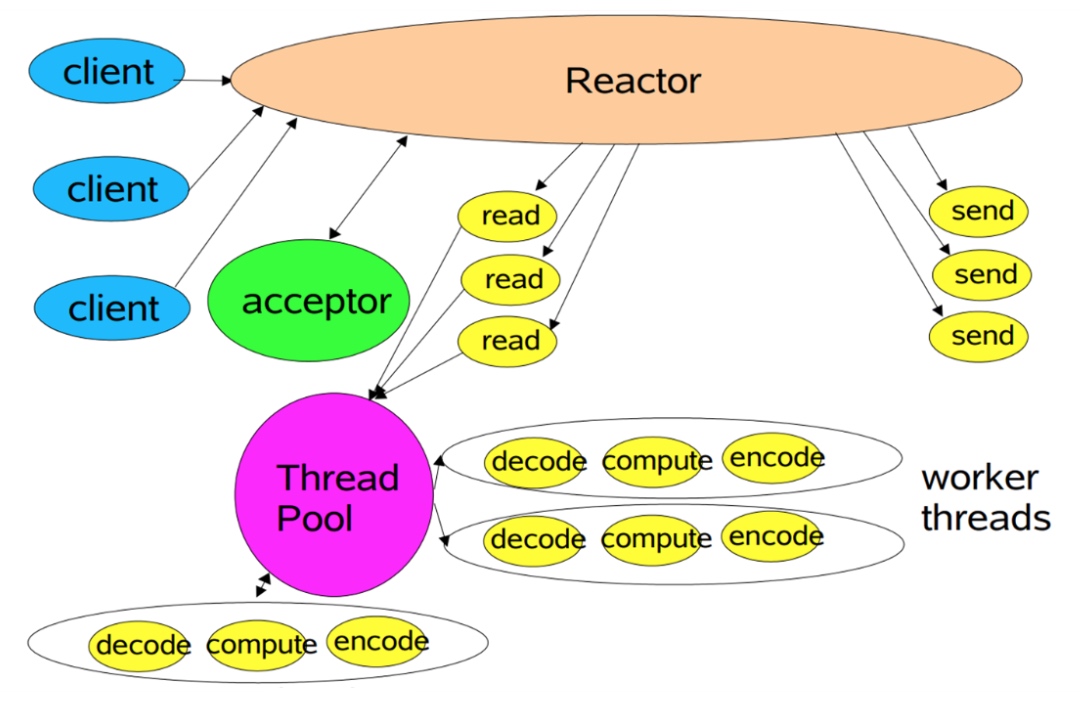
-
Reactore模式v3:主从多线程
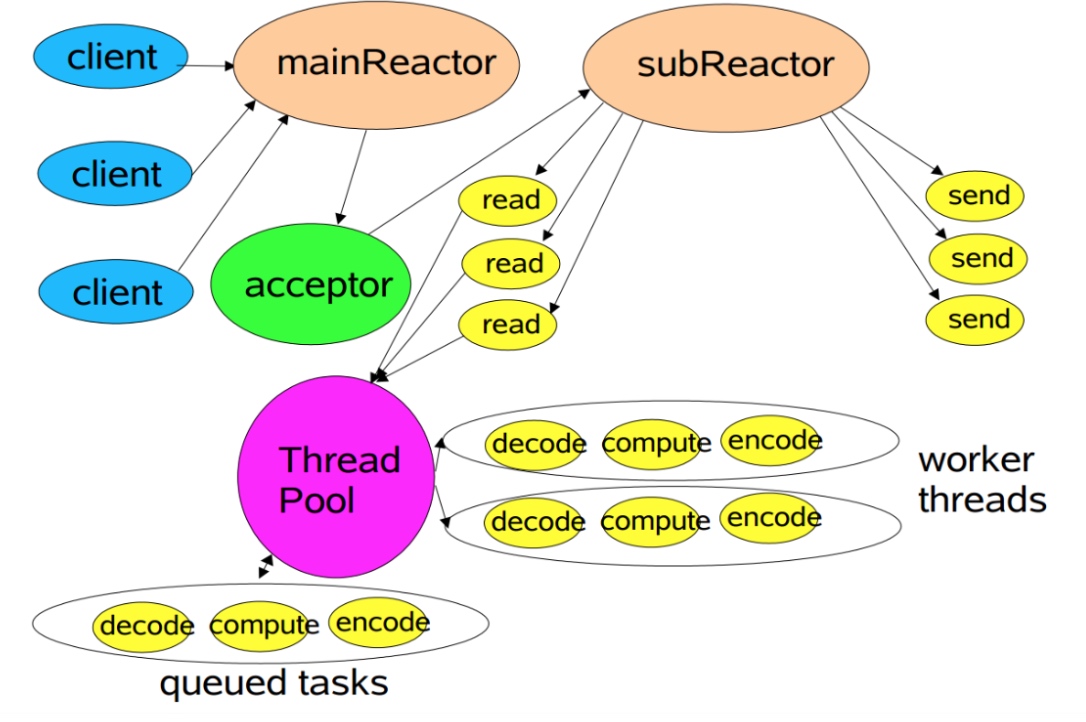
2.3. 如何使用三种Reactor模式
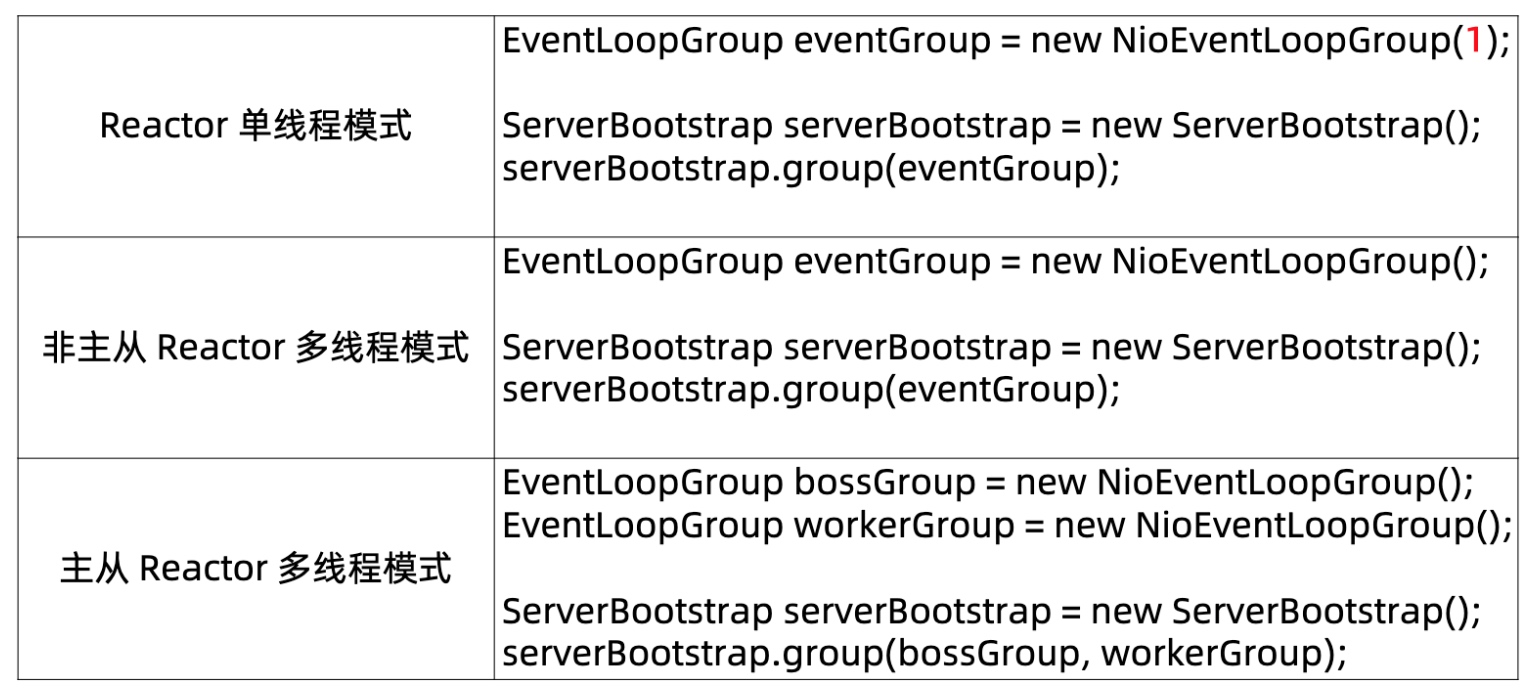
2.4. Reactor相关源码分析
- Netty 如何支持主从 Reactor 模式的?
- 为什么说 Netty 的 main reactor 大多并不能用到一个线程组,只能线程组里面的一个?
- Netty 给 Channel 分配 NIO event loop 的规则是什么
- 通用模式的 NIO 实现多路复用器是怎么跨平台的
3. TCP 粘包/半包 Netty 全搞定
3.1. 什么是粘包和半包?
3.2. 为什么 TCP 应用中会出现粘包和半包现象?
粘包的主要原因:
- 发送方每次写入数据 < 套接字缓冲区大小
- 接收方读取套接字缓冲区数据不够及时
半包的主要原因:
- 发送方写入数据 > 套接字缓冲区大小
- 发送的数据大于协议的 MTU(Maximum Transmission Unit,最大传输单元),必须拆包

换个角度看:
- 收发
- 一个发送可能被多次接收,多个发送可能被一次接收
- 传输
- 一个发送可能占用多个传输包,多个发送可能公用一个传输包
根本原因:
- TCP 是流式协议,消息无边界。
3.3. 解决粘包和半包问题的几种常用方法
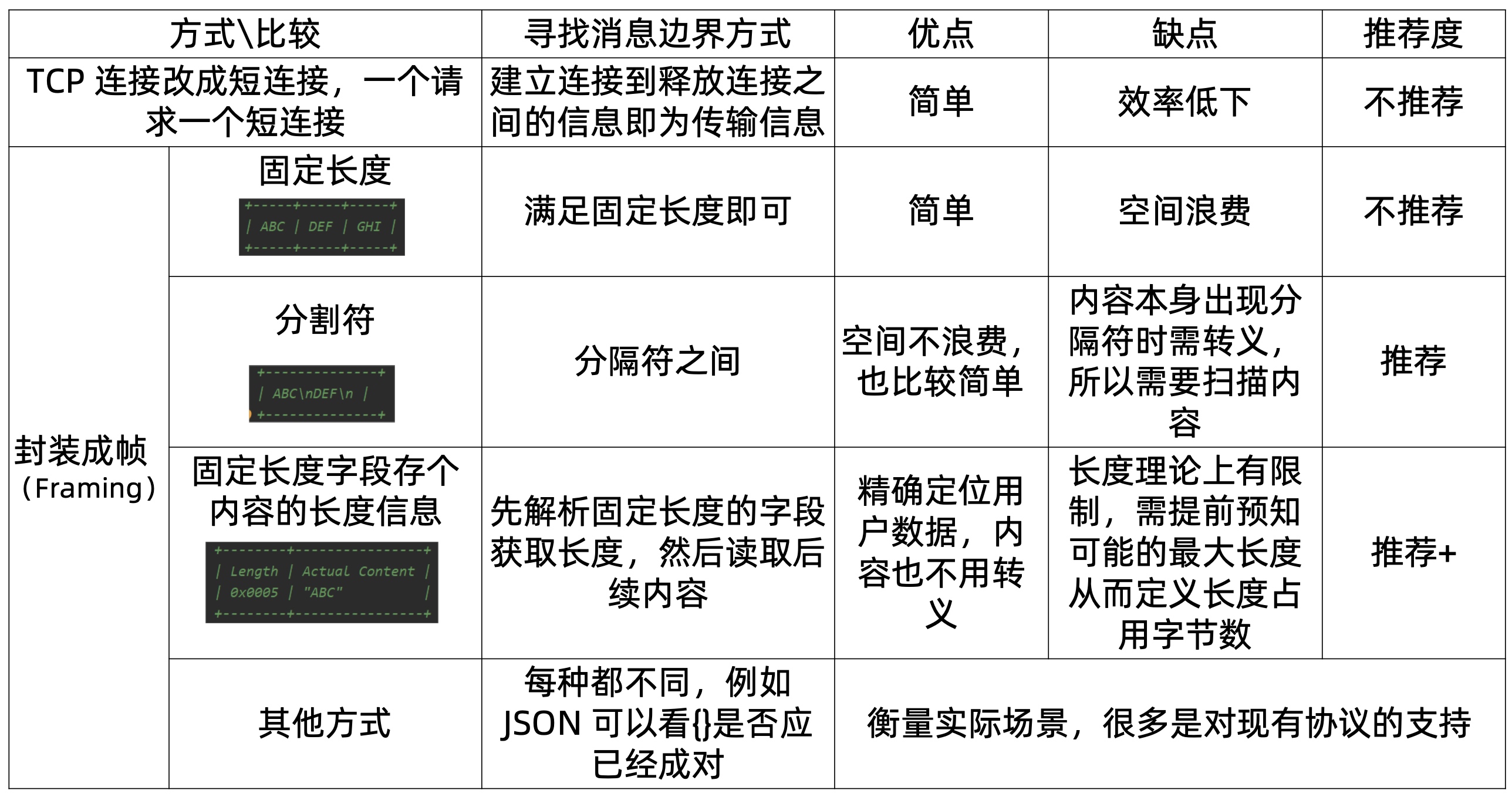
3.4. Netty 对三种常用封帧方式的支持

3.5. 解读 Netty 处理粘包、半包的源码
4. 常用的“二次”编解码方式
4.1. 为什么要“二次”解码?
Java对象和字节流之间相互转换。
4.2. 常用的“二次编解码”方式
- Java序列化
- Marshaling
- XML
- JSON
- MessagePack
- Protobuf
- 其他
4.3. 选择编解码方式的要点
- 大小
- 速度
- 可读性
4.4. Protobuf简介与适用
- 工具生成对应相等代码
4.5. 源码解读:Netty对二次编解码的支持
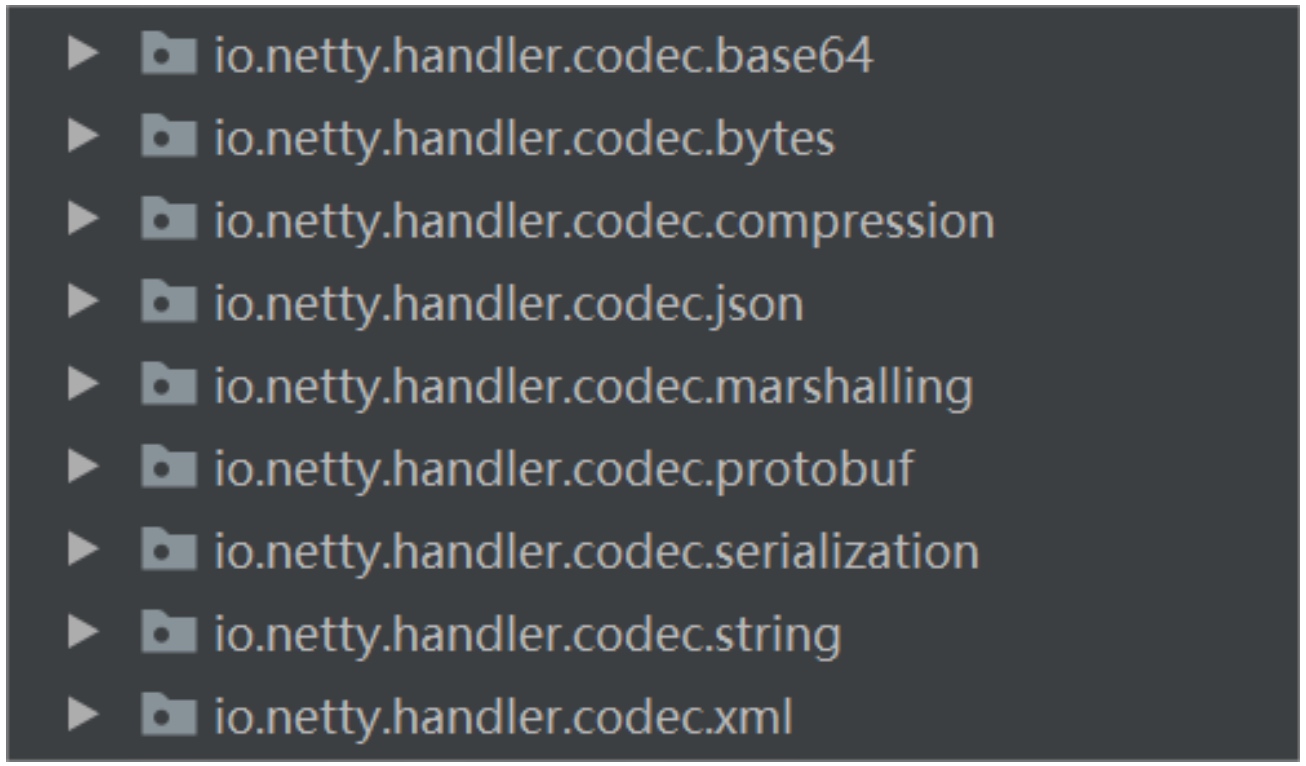
ch.pipeline().addLast(new ProtobufVarint32FrameDecoder());
ch.pipeline().addLast(new ProtobufDecoder(PersonOuterClass.Person.getDefaultInstance())); ch.pipeline().addLast(new ProtobufVarint32LengthFieldPrepender()); ch.pipeline().addLast(new ProtobufEncoder());
5. keepalive 与 Idle 监测
5.1. 为什么需要keepalive?
生活中的例子:
如果打电话中别人忽然不说话了,你会问一句“你还在吗?”,如果没有回复,就挂断。
好处:
避免长时间占用线路,别人就打不进来了
5.2. 怎么设计keepalive?以TCP keepalive 为例
TCP keepalive 核心参数:
# sysctl -a|grep tcp_keepalive
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
当启用(默认关闭)keepalive 时,TCP 在连接没有数据
通过的7200秒后发送 keepalive 消息,当探测没有确认时, 按75秒的重试频率重发,一直发 9 个探测包都没有确认,就认定 连接失效。
所以总耗时一般为:2 小时 11 分钟 (7200 秒 + 75 秒* 9 次)
5.3. 为什么还需要应用层keepalive?
- 协议分层,各层关注点不同:
传输层关注是否“通”,应用层关注是否可服务? 类比前面的电话订餐例子,电话能通, 不代表有人接;服务器连接在,但是不定可以服务(例如服务不过来等)。 - TCP 层的 keepalive 默认关闭,且经过路由等中转设备 keepalive 包可能会被丢弃。
- TCP 层的 keepalive 时间太长:
默认 > 2 小时,虽然可改,但属于系统参数,改动影响所有应用。
5.4. idle监测是什么?
生活例子:
在打电话时,如果别人忽然不讲讲话了,隔一段时间后,你会问“你还在吗?”
总结:
Idle监测用做诊断,配合keepalive,减少keepalive消息。
Idle监测的演进:
v1:定时发送监测消息。
v2:有其他数据传输时,不发送监测消息。无数据传输时,定时发送监测消息。
5.5. 如何在Netty中开启TCP keepalive 和Idle监测?
- Server 端开启 TCP keepalive
bootstrap.childOption(ChannelOption.SO_KEEPALIVE,true) bootstrap.childOption(NioChannelOption.of(StandardSocketOptions.SO_KEEPALIVE), true)
提示:.option(ChannelOption.SO_KEEPALIVE,true) 存在但是无效
- 开启不同的 Idle Check:
ch.pipeline().addLast(“idleCheckHandler", new IdleStateHandler(0, 20, 0, TimeUnit.SECONDS));
5.6. 源码解读 Netty 对 TCP keepalive 和三种 Idle 检测的支持
源码解读:
- 设置 TCP keepalive 怎么生效的?
- 调用jdk接口,设置chennel的option
- 两种设置 keepalive 的方式有什么区别?
- 没啥区别,一个是netty抽象的,一个是nio的
- Idle 检测类包(io.netty.handler.timeout)的功能浏览
- 读 Idle 检测的原理
- 写 Idle 检测原理和参数 observeOutput 用途?
6. Netty 的那些“锁”事
6.1. 分析同步问题的核心三要素
- 原子性
- 可见性
- 有序性
6.2. 锁的分类
- 对竞争的态度:乐观锁(java.util.concurrent 包中的原子类)与悲观锁(Synchronized)
- 等待锁的人是否公平而言:公平锁 new ReentrantLock (true)与非公平锁 new ReentrantLock ()
- 是否可以共享:共享锁与独享锁:ReadWriteLock ,其读锁是共享锁,其写锁是独享锁
6.3. Netty玩转锁的五个关键点:
- 在意锁的对象和范围 -> 减少粒度
- 注意所得对象本身大小 -> 减少空间占用
- 注意锁的速度 -> 提高速度
- 不同场景选择不同的并发类 -> 因需而变
- 衡量好锁的价值 -> 能不能则不用
7. Netty 如何玩转内存使用
7.1. 内存使用技巧的目标
目标:
- 内存占用少(空间)
- 应用速度快(时间)
对 Java 而言:减少 Full GC 的 STW(Stop the world)时间
7.2. Netty 内存使用技巧 - 减少对像本身大小
例 1:用基本类型就不要用包装类:
例 2: 应该定义成类变量的不要定义为实例变量:
例 3: Netty 中结合前两者:
io.netty.channel.ChannelOutboundBuffer#incrementPendingOutboundBytes(long, boolean) 统计待写的请求的字节数
7.3. Netty 内存使用技巧 - 对分配内存进行预估
例 1:对于已经可以预知固定 size 的 HashMap避免扩容
可以提前计算好初始size或者直接使用 com.google.common.collect.Maps#newHashMapWithExpectedSize
例 2:Netty 根据接受到的数据动态调整(guess)下个要分配的 Buffer 的大小。可参考 io.netty.channel.AdaptiveRecvByteBufAllocator
7.4. Netty 内存使用技巧 - Zero-Copy
例 1:使用逻辑组合,代替实际复制。
例如 CompositeByteBuf: io.netty.handler.codec.ByteToMessageDecoder#COMPOSITE_CUMULATOR
例 2:使用包装,代替实际复制。
byte[] bytes = data.getBytes();
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
例 3:调用 JDK 的 Zero-Copy 接口。
Netty 中也通过在 DefaultFileRegion 中包装了 NIO 的 FileChannel.transferTo() 方法实 现了零拷贝:io.netty.channel.DefaultFileRegion#transferTo
7.5. Netty 内存使用技巧 - 堆外内存
优点:
- 更广阔的“空间 ”,缓解店铺内压力 -> 破除堆空间限制,减轻 GC 压力
- 减少“冗余”细节(假设烧烤过程为了气氛在室外进行:烤好直接上桌:vs 烤好还 要进店内)-> 避免复制
缺点:
- 需要搬桌子 -> 创建速度稍慢
- 受城管管、风险大 -> 堆外内存受操作系统管理
7.6. Netty 内存使用技巧 - 内存池
为什么引入对象池:
- 创建对象开销大
- 对象高频率创建且可复用
- 支持并发又能保护系统
- 维护、共享有限的资源
如何实现对象池?
- 开源实现:Apache Commons Pool
- Netty 轻量级对象池实现 io.netty.util.Recycler
7.7. 源码解读Netty 内存使用
源码解读:
- 怎么从堆外内存切换堆内使用?以UnpooledByteBufAllocator为例
- 堆外内存的分配本质?
- 内存池/非内存池的默认选择及切换方式?
io.netty.channel.DefaultChannelConfig#allocator - 内存池实现(以 PooledDirectByteBuf 为例)
io.netty.buffer.PooledDirectByteBuf