
算法学习笔记
1. 常见数据结构解析
1.1. 堆
- 简介:
- 堆是一个完全二叉树,用数组进行存储。
- 假设数组头结点不存储元素,那么
- 任意节点的n子节点是2n和2n+1
- 任意节点的父节点是n/2
- 特性:
- 完全二叉树
- 任一节点比他的子节点 大/小
- 各种操作:
- 插入(小顶堆为例):
- 把要插入的元素放在堆的最后一个位置,
- 该元素和父节点比较,如果比父节点小则互换
- 直到找到父元素比插入元素小或者到了堆顶
- 时间复杂度 O(logn)
- 查找:
- 堆顶元素为最小值
- 时间复杂度 O(1)
- 删除:
- 堆顶和元素最后一个元素互换位置
- 前(n-1)个元素进行堆化
- 时间复杂度O(logn)
- 建堆:
- 重复进行插入操作
- 时间复杂度O(n)
- 推导:

- 推导:
- 应用
- 排序:时间复杂度O(nlogn) 空间复杂度O(1)
- 插入(小顶堆为例):
1.2. 平衡二叉搜索树
-
定义
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 -
和AVL树的管理
AVL树是平衡二叉树的一种实现 -
AVL树缺点
插入、删除元素的时候自平衡的过程非常复杂
1.3. 红黑树
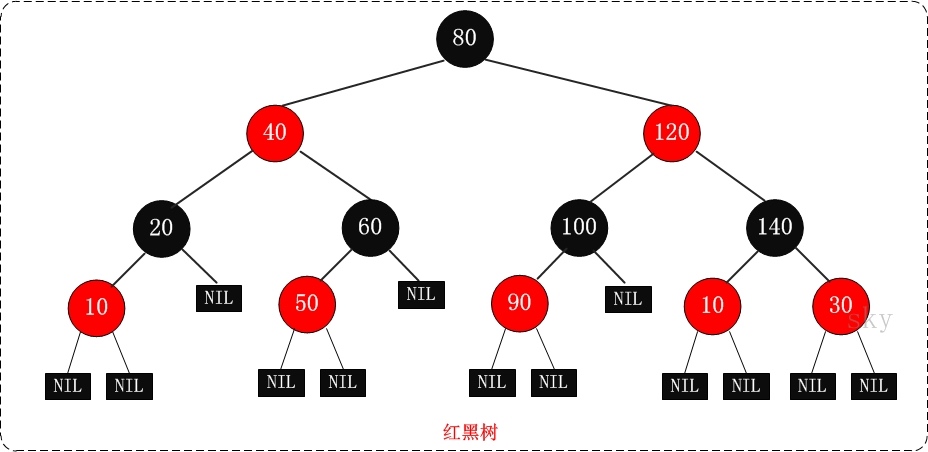
牺牲了严格的高度平衡的优越条件为代价,实现
- 以O(log2 n)的时间复杂度进行搜索、插入、删除操作
- 任何不平衡都会在三次旋转之内解决。
1.4. B树
B树也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
一颗m阶的B树定义如下:
1)每个结点最多有m-1个关键字。
2)根结点最少可以只有1个关键字。
3)非根结点至少有Math.ceil(m/2)-1个关键字。
4)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
5)所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。
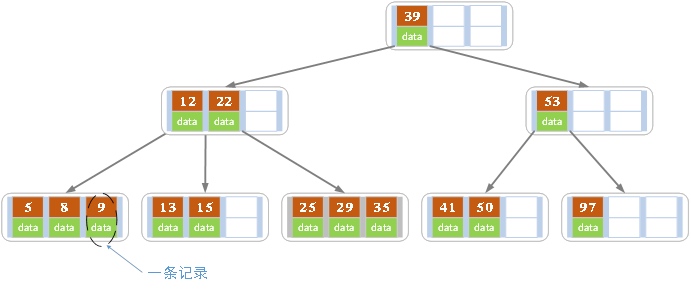
上图是一颗阶数为4的B树。在实际应用中的B树的阶数m都非常大(通常大于100),所以即使存储大量的数据,B树的高度仍然比较小。每个结点中存储了关键字(key)和关键字对应的数据(data),以及孩子结点的指针。我们将一个key和其对应的data称为一个记录。但为了方便描述,除非特别说明,后续文中就用key来代替(key, value)键值对这个整体。在数据库中我们将B树(和B+树)作为索引结构,可以加快查询速速,此时B树中的key就表示键,而data表示了这个键对应的条目在硬盘上的逻辑地址。
1.5. B+树
各种资料上B+树的定义各有不同,一种定义方式是关键字个数和孩子结点个数相同。这里我们采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。上图就是一颗阶数为4的B+树。
除此之外B+树还有以下的要求。
- B+树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
- B+树与B树最大的不同是内部结点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子结点中。
- m阶B+树表示了内部结点最多有m-1个关键字(或者说内部结点最多有m个子树),阶数m同时限制了叶子结点最多存储m-1个记录。
- 内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
- 每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
1.5.1. B树和B+树区别
- B+树中只有叶子节点会带有指向记录的指针(ROWID),而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。
- B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
- B+树的优点
- 非叶子节点不会带上ROWID,这样,一个块中可以容纳更多的索引项,一是可以降低树的高度。二是一个内部节点可以定位更多的叶子节点。
- 叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。
- B树的优点:
- 对于在内部节点的数据,可直接得到,不必根据叶子节点来定位。
1.6. 跳表
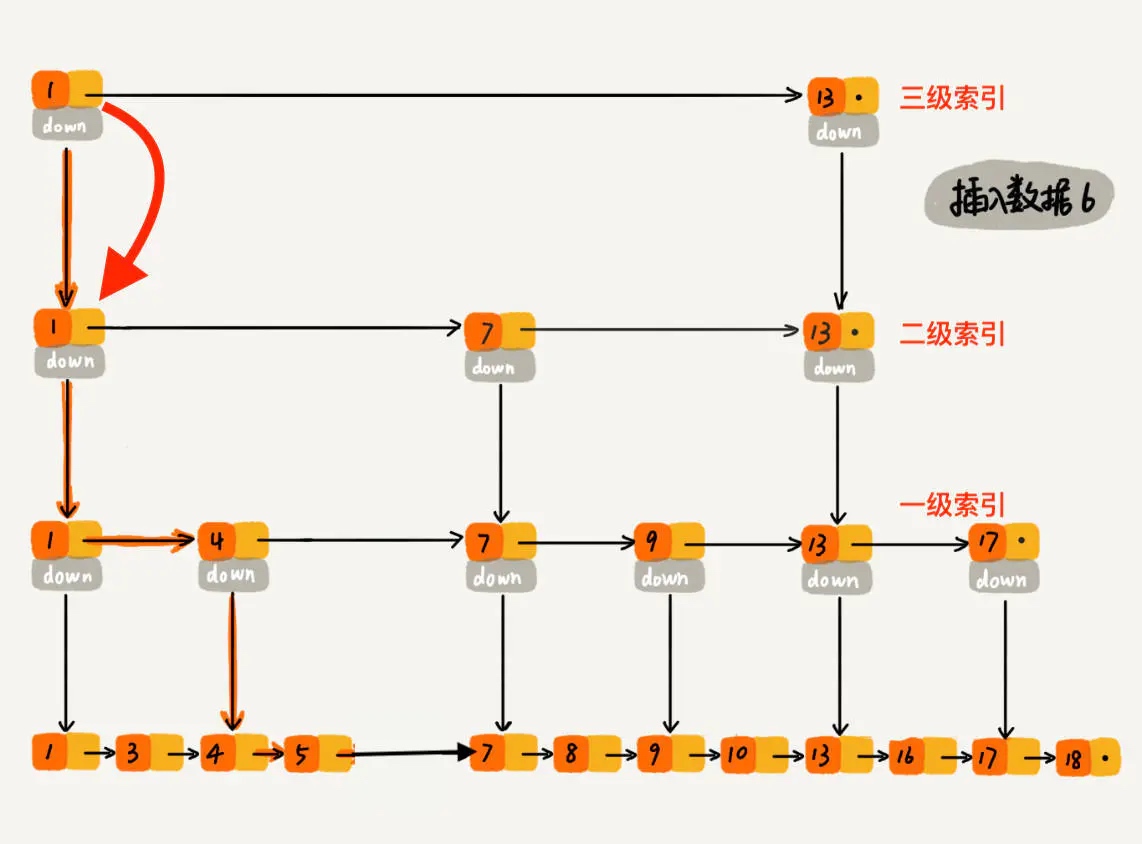
- 空间复杂度:O(n)
- 查询复杂度:O(logn)
- 插入复杂度:O(logn)
- 实现方式:
- 实现一个 randomLevel() 方法,该方法会随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数)
- randomLevel() 方法返回 1 表示当前插入的该元素不需要建索引,只需要存储数据到原始链表即可(概率 1/2)
- randomLevel() 方法返回 2 表示当前插入的该元素需要建一级索引(概率 1/4)
- randomLevel() 方法返回 3 表示当前插入的该元素需要建二级索引(概率 1/8)
- randomLevel() 方法返回 4 表示当前插入的该元素需要建三级索引(概率 1/16)
- 以此类推
- 删除复杂度:O(logn)
1.7. trie树10
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
2. 练习题
2.1. 链表
83. 删除排序链表中的重复元素
82. 删除排序链表中的重复元素 II
206. 反转链表
92. 反转链表 II
21. 合并两个有序链表
86. 分隔链表
148. 排序链表
143. 重排链表
141. 环形链表
142. 环形链表 II
234. 回文链表
138. 复制带随机指针的链表
2.2. 栈和队列
- 栈:
// 最好用
Deque<String> stack = new ArrayDeque<>();
// 也可以用
Stack<String> stack = new Stack<>();
stack.push();
stack.pop();
stack.peek();
- 队列
Queue<String> queue = new LinkedList<String>();
queue.offer("a");
String s= queue.poll;
155. 最小栈
150. 逆波兰表达式求值
394. 字符串解码
94. 二叉树的中序遍历
133. 克隆图
200. 岛屿数量
84. 柱状图中最大的矩形
232. 用栈实现队列
542. 01 矩阵
2.3. 二叉树
104. 二叉树的最大深度
110. 平衡二叉树
124. 二叉树中的最大路径和
236. 二叉树的最近公共祖先
102. 二叉树的层序遍历
107. 二叉树的层序遍历 II
103. 二叉树的锯齿形层序遍历
98. 验证二叉搜索树
701. 二叉搜索树中的插入操作
2.4. 二分搜索
35. 搜索插入位置
74. 搜索二维矩阵
240. 搜索二维矩阵 II
278. 第一个错误的版本
153. 寻找旋转排序数组中的最小值
154. 寻找旋转排序数组中的最小值 II
33. 搜索旋转排序数组
81. 搜索旋转排序数组 II
2.5. 滑动窗口
- 总结要点:
- 第一层循环右移
- 第二层循环左移
- 第三层判断更新结果
2.6. 二进制
136. 只出现一次的数字
137. 只出现一次的数字 II
260. 只出现一次的数字 III
191. 位1的个数
338. 比特位计数
190. 颠倒二进制位
2.7. 排序算法
- 快速排序 sort-an-array
- 支点递归算法
- 归并排序 sort-an-array
- 拆分合并算法
- 堆排序 sort-an-array
- 堆排序:建堆去顶算法
- 建堆:自下向上堆化
- 堆化:自上向下确定父子
2.8. 动态规划
2.8.1. Matrix DP (10%)
120. 三角形最小路径和
62. 不同路径
63. 不同路径 II
2.8.2. Sequence (40%)
70. 爬楼梯
55. 跳跃游戏
45. 跳跃游戏 II
300. 最长递增子序列
139. 单词拆分
96. 不同的二叉搜索树
2.8.3. Two Sequences DP (40%)
2.8.4. Backpack & Coin Change (10%)
2.9. 递归
344. 反转字符串
24. 两两交换链表中的节点
509. 斐波那契数
2.10. 回溯
78. 子集
90. 子集 II
46. 全排列
47. 全排列 II
131. 分割回文串