
并发学习笔记
- 四、并发编程基础
- 1、为什么使用多线程
- 2、如何设置线程优先级
- 3、线程有哪些状态
- 4、如何达到线程的各种状态
- 5、线程各种状态之间如何转换
- 6、Daemon线程有什么特点,如何创建Daemon线程
- 7、线程的中断是什么,如何进行中断相关操作
- 8、中断有什么用?
- 9、suspend()、resume()和stop()作用
- 10、使用 stop/interrupt 结束进程有什么区别?
- 11、synchronized底层实现原理?
- 12、如何实现 等待/通知 机制?
- 13、如何实现线程间的 管道输入/输出流?
- 14、Thread.join()有什么用?
- 15、ThreadLocal如何使用?
- 16、如何实现等待超时模式?
- 17、如何使用线程池?
- 17、如何实现一个简单的线程池?
- 18、如何用线程池实现简单的Web服务器?
- 五、Java中的锁
- 1、synchronized 和 Lock接口 比较优缺点?
- 2、Lock 接口如何使用?
- 3、如何实现独占锁?
- 4、AbstractQueuedSynchronizer 内部如何实现?
- 5、LockSupport的用途?
- 6、LockSupport的park/unpark与 object.wait/notify的区别?
- 7、如何实现TwinsLock?
- 8、什么是『重入锁』?如何实现『重入锁』?
- 9、『公平锁』和『非公平锁』区别?如何实现?
- 10、『读写锁』如何使用?如何实现『读写锁』?
- 11、除了
wait()+notify()+synchronize(),如何实现『等待/通知』模式? - 12、Condition内部如何实现?
Redis笔记
1. 基础
1.1. Redis持久化
- AOF
- 落盘实际:always\every second\no
- 问题:AOF越来越大
- 解决:AOF文件重写
- 重写机制过程:
- 主线程,fork一个子线程
- 主线程,一边把新增操作写到aof文件a中,一边把新增操作写到临时缓存x中
- 子线程,把旧的aof文件重写为一个新的aof文件b,然后通知主线程。
- 主线程,把缓存区x的数据写到aof文件b中,然后切换aof文件到b。
- RDB
- 快照时数据能修改吗?如何做到允许同时修改?
- bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。
- bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。
- 主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响。
- 主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本(键值对 C’)。然后,主线程在这个数据副本上进行修改。同时,bgsave 子进程可以继续把原来的数据(键值对 C)写入 RDB 文件。
- 快照时数据能修改吗?如何做到允许同时修改?
关于 AOF 和 RDB 的选择问题,我想再给你提三点建议:
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择;
- 如果允许分钟级别的数据丢失,可以只使用 RDB;
- 如果只用 AOF,优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
1.2. 如何保障主从数据一致性?
- 读写分工:写,只能主库;读,可以主or从。
- 同步阶段:replicaof命令之后,先通过rdb完成初始化同步,后续增量同步
- 异常恢复:如果主从网络断开,主库预留缓冲区记录断联期间的数据变更。
1.3. 哨兵机制
Redis 的哨兵机制自动完成了以下三大功能,从而实现了主从库的自动切换,可以降低 Redis 集群的运维开销:
- 监控主库运行状态,并判断主库是否客观下线;
- 在主库客观下线后,选取新主库;
- 选出新主库后,通知从库和客户端。
为了避免单个哨兵故障后无法进行主从切换,以及为了减少误判率,又引入了哨兵集群;哨兵集群又需要有一些机制来支撑它的正常运行。
- 基于 pub/sub 机制的哨兵集群组成过程;
- 基于 INFO 命令的从库列表,这可以帮助哨兵和从库建立连接;
- 基于哨兵自身的 pub/sub 功能,这实现了客户端和哨兵之间的事件通知。
- 哨兵集群在判断了主库“客观下线”后,经过投票仲裁,选举一个 Leader 出来,由它负责实际的主从切换,即由它来完成新主库的选择以及通知从库与客户端。
1.4. redis的分片
在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。
数据重新分布的原因:
- 集群的实例增减,
- 为了实现负载均衡而进行的数据重新分布
会导致哈希槽和实例的映射关系发生变化,客户端发送请求时,会收到命令执行报错信息
- MOVED:
- 客户端更新映射表 && 请求另外一个实例
- ASK
- 客户端不会更新映射表 && 请求另外一个实例
2. 实践
2.1. 如何用作旁路缓存
- 只读缓存
- 读:先读缓存,缓存没有读DB,再写回缓存
- 写:先删缓存,再改DB
- 读写缓存
- 同步写回策略
- 好处:保证一致性
- 不足:性能较差
- 异步写回策略
- 好处:性能较好
- 不足:可能存在不一致
- 同步写回策略
2.2. 读写缓存,如何避免数据不一致
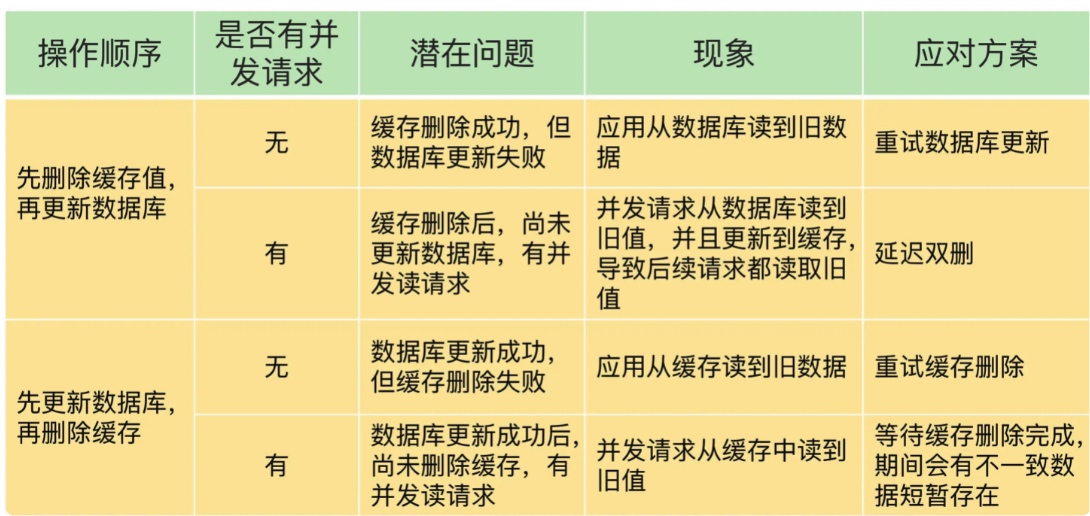
- 问题1:删除缓存值或更新数据库失败而导致数据不一致
- 可以使用重试机制确保删除或更新操作成功。
- 问题2:在删除缓存值、更新数据库的这两步操作中,有其他线程的并发读操作,导致其他线程读取到旧值
- 方案1:先改DB,再删缓存
- 方案2:延迟双删
2.3. 如何解决 雪崩、击穿、穿透问题
- 雪崩
- 原因:
- 大量缓存同时过期
- 服务器挂掉
- 应对:
- 合理设置缓存时间
- 服务降级
- 服务熔断
- 请求限流
- redis部署主从集群
- 原因:
- 击穿
- 原因:
- 热点数据过期
- 应对:
- 热点数据不要设置过期时间
- 热点数据在还没有过期时,异步(kafka或者消息)重新加载缓存
- 热点数据在读库的时间,先加一把分布式锁
- 原因:
- 穿透
- 原因:
- 空数据
- 应对:
- 缓存进行空保护
- 布隆过滤器
- 业务层拦截空请求
- 原因:
2.4. 替换策略是怎样的
候选范围:
- 所有数据都是候选集
- 设置了过期时间的数据是候选集
淘汰策略:
- 随机选择,
- 根据 LRU 算法选择,
- 根据 LFU 算法选择
- 根据数据离过期时间的远近来决定
2.5. 如何应对并发访问
“读取 - 修改 - 写回”操作(Read-Modify-Write,简称为 RMW 操作)需要原子执行
current = GET(id)
current--
SET(id, current)
- 方法1:原子操作
- 原子操作命令,例如 INCR、DECR
- lua脚本,例如需要限制每个IP 每分钟限制访问20次
//获取ip对应的访问次数
current = GET(ip)
//如果超过访问次数超过20次,则报错
IF current != NULL AND current > 20 THEN
ERROR "exceed 20 accesses per second"
ELSE
//如果访问次数不足20次,增加一次访问计数
value = INCR(ip)
//如果是第一次访问,将键值对的过期时间设置为60s后
IF value == 1 THEN
EXPIRE(ip,60)
END
//执行其他操作
DO THINGS
END
- 方法2:加分布式锁
LOCK()
current = GET(id)
current--
SET(id, current)
UNLOCK()
2.6. 如何实现分布式锁?
- 加锁操作
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端。
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
- 解锁操作
- 释放锁也包含了读取锁变量值、判断锁变量值和删除锁变量三个操作,
- 无法使用单个命令来实现,采用 Lua 脚本执行释放锁操作,通过 Redis 原子性地执行 Lua 脚本,来保证释放锁操作的原子性。
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
-
进一步提升锁的可靠性:Redlock算法
-
实践:使用Redisson
2.7. 如何实现秒杀?
- 方法1:使用lua脚本保证原子性
key: itemID
value: {total: N, ordered: M}
#获取商品库存信息
local counts = redis.call("HMGET", KEYS[1], "total", "ordered");
#将总库存转换为数值
local total = tonumber(counts[1])
#将已被秒杀的库存转换为数值
local ordered = tonumber(counts[2])
#如果当前请求的库存量加上已被秒杀的库存量仍然小于总库存量,就可以更新库存
if ordered + k <= total then
#更新已秒杀的库存量
redis.call("HINCRBY",KEYS[1],"ordered",k) return k;
end
return 0
客户端会根据脚本的返回值,来确定秒杀是成功还是失败了。
如果返回值是 k,就是成功了;如果是 0,就是失败。
- 方法2:使用分布式锁保证原子性
使用分布式锁来支撑秒杀场景的具体做法是,先让客户端向 Redis 申请分布式锁,只有拿到锁的客户端才能执行库存查验和库存扣减。
//使用商品ID作为key
key = itemID
//使用客户端唯一标识作为value
val = clientUniqueID
//申请分布式锁,Timeout是超时时间
lock =acquireLock(key, val, Timeout)
//当拿到锁后,才能进行库存查验和扣减
if(lock == True) {
//库存查验和扣减
availStock = DECR(key, k)
//库存已经扣减完了,释放锁,返回秒杀失败
if (availStock < 0) {
releaseLock(key, val)
return error
}
//库存扣减成功,释放锁
else{
releaseLock(key, val)
//订单处理
}
}
//没有拿到锁,直接返回
else
return
2.8. 如何实现ACID
-
A 原子性:通过 MULTI、EXEC、DISCARD 和 WATCH 四个命令来支持事务机制
-
C 一致性:根据不同情况进行分析
情况一:命令入队时就报错在这种情况下,事务本身就会被放弃执行,所以可以保证数据库的一致性。
情况二:命令入队时没报错,实际执行时报错在这种情况下,有错误的命令不会被执行,正确的命令可以正常执行,也不会改变数据库的一致性。
情况三:EXEC 命令执行时实例发生故障在这种情况下,实例故障后会进行重启,这就和数据恢复的方式有关 -
I 隔离性:
- 并发操作在 EXEC 命令前执行,
- 隔离性的保证要使用 WATCH 机制来实现,
- 否则隔离性无法保证;
- 并发操作在 EXEC 命令后执行,此时,隔离性可以保证。
- 并发操作在 EXEC 命令前执行,
-
D 持久性:
- 不管 Redis 采用什么持久化模式,事务的持久性属性是得不到保证的
