VPN 和 代理 的工作原理
1. 导语
日常会遇到一些问题:
- tunnelblick 和 surge一起使用的时候会不会冲突?
- tunnelblick 的原理是怎样的?
- surge的工作原理是怎样的?
- 使用tunnelblick 时访问网站很慢,怎么解决?
mac文件体系
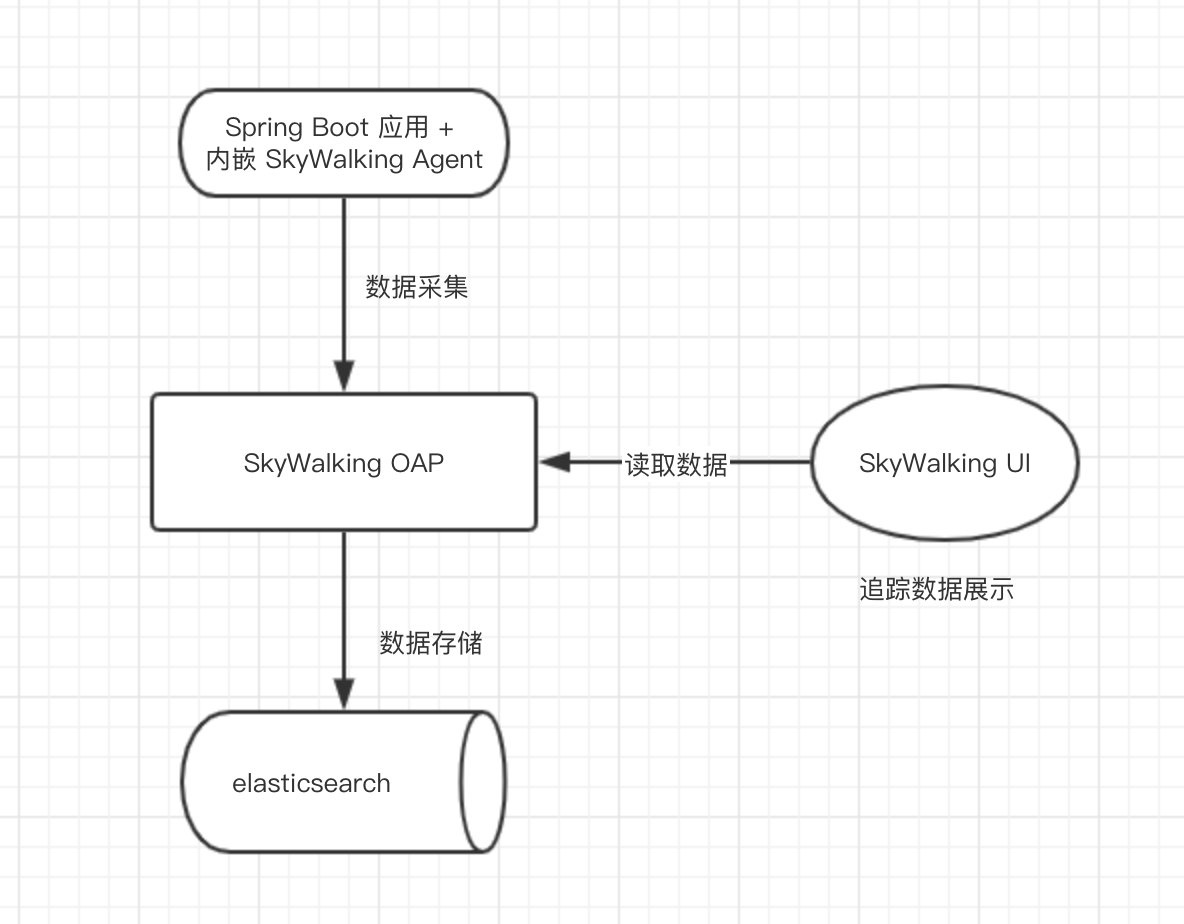
APM分享:如何实现无侵入APM
1. APM概述
APM 通常认为是 Application Performance Management 的简写,它主要有三个方面的内容,分别是 Logs(日志)、Traces(链路追踪) 和 Metrics(报表统计)。
Read on →